Project Overview
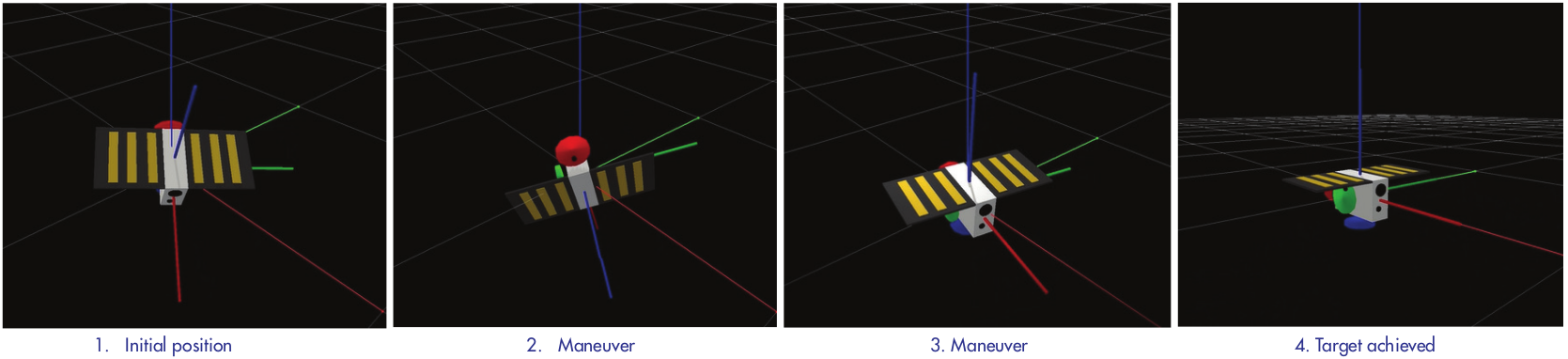
REACT investigates the application of Deep Reinforcement Learning for satellite attitude control, addressing critical challenges in space systems autonomy. This research developed robust control policies that handle both nominal operations and critical underactuated scenarios — where one or more reaction wheels have failed.
Conducted during my MSc thesis and continued at Argotec, this foundational work directly contributed to the autonomous navigation algorithms later deployed on embedded flight hardware aboard LICIACube (NASA DART mission) and ArgoMoon (NASA Artemis I mission). The ability to handle actuator uncertainty in simulation proved critical for building confidence in real flight systems.